

Gate AI on the Public Prompt-Injection Leaderboard
A look at where Gate AI lands across 16 public benchmarks, how the comparison was kept honest, and what the methodology checks rule out.
Introducing Gate AI
Today we announced Constellation Gate AI, a security and audit gateway for AI applications. The product launches in June 2026, and early access registration is open today. Gate AI plugs into any existing AI workflow without code changes and provides prompt-injection defense, a tamper-evident audit trail of every model call, and unified cost and usage visibility across major commercial model APIs and open-weight models.
Prompt injection is the class of attack where malicious instructions hidden inside emails, documents, websites, or other content retrieved by an AI agent cause that agent to take actions its operator did not intend. As AI agents increasingly execute real work on behalf of users and organizations, the security layer for those agents has to sit inline with every model call.
Gate AI is the newest product from Constellation Network's broader work at the intersection of AI and blockchain. A fuller introduction to the product will follow. This post is about the technical benchmark report we're publishing alongside the announcement.
About this report
Published evaluations of prompt-injection detectors are uneven. Two systems can both claim "F1 of 95%" while quietly using per-dataset threshold tuning, undisclosed operating points, or test corpora that overlap with their training data. A buyer reading those numbers has no way to tell which detector would actually catch more attacks at the same false-positive budget on traffic they haven't seen.
We didn't want Gate AI to launch into that mess without showing our work. Today we're also publishing the technical report behind it: Gate AI: LLM Security Benchmark Evaluation Methodology & Results, authored by Ryle Goehausen and Marcus Sousa from the Constellation Network engineering team. The report evaluates Gate AI's prompt-injection detection cascade across 16 public benchmarks, 12,111 samples, with a single global threshold applied uniformly across every dataset.
Headline results. Across the 16 benchmarks, Gate AI catches roughly 95 out of every 100 prompt injection attempts at a strict 1-in-100 false-alarm cap, and ranks first on 8 of the 16 benchmarks against published competitor scores. Median response time is 53ms.
What follows is how we measured it, and what the numbers do and don't say.
Why a single operating point matters
The most common shortcut in published prompt-injection evaluations is per-dataset threshold tuning. A detector's decision threshold is set separately on each benchmark, picked to maximize F1 on that benchmark in isolation. The resulting per-benchmark numbers look strong, but they describe a detector that knows the test distribution in advance. Real production traffic has no such labels.
The Gate AI evaluation enforces the opposite. A single global threshold is selected once, on held-out folds, to maximize F1 subject to a pooled FPR cap of 1% across the entire 16-dataset corpus. That same threshold is then applied to every dataset. Some benchmarks land above the global FPR cap, some land well below, and the reported numbers reflect that reality.
A second design choice: every external comparison is evaluated at per-dataset matched FPR. Where a competitor publishes both a primary metric and an FPR, Gate's threshold is re-tuned for that comparison to hit the competitor's published FPR. Where the competitor publishes a smaller evaluation set than ours, we report a sample-size-matched bootstrap confidence interval so the reader can see whether the claimed difference is inside or outside sampling noise.
These choices are not free. F1 numbers reported under them sit a few points below what per-dataset tuning would produce. The tradeoff is that the numbers we report are the numbers a buyer can ship with.
What we evaluated
The corpus combines 16 public benchmarks across three categories:
- Balanced collections with both injection and benign samples (deepset, jackhhao, safeguard, the gentel-bench suite, bipia, ilion-bench, and others).
- All-attack adversarial corpora where every sample is a known injection (advbench, harmbench, hackaprompt, garak, llmail, multijail, salad-data, strongreject, evasion-attacks, gandalf-ignore, injecagent, chatgpt-jailbreak).
- All-benign collections where every sample is a legitimate user prompt (notinject, wildguard-benign). On these, false-positive rate is the only meaningful metric. It tells you what fraction of real user traffic the detector mistakenly blocks.
We deliberately added benchmark families covering indirect injection (instructions hidden in retrieved content), encoding evasion (instructions disguised through unicode or base64 tricks), goal hijacking, prompt leaking, and over-defense on legitimate user prompts. The composition is documented dataset-by-dataset in the paper so readers can audit what's in and what's out.
Evaluation runs use 5-fold StratifiedKFold cross-validation as the headline pass, with a parallel StratifiedGroupKFold pass over a composite key (parent-prompt id plus MinHash near-duplicate clusters at Jaccard ≥ 0.8) as a leakage diagnostic. The gap between the two passes quantifies any residual leakage between train and test folds. If a model is leaning on near-duplicate matching to inflate its score, this diagnostic catches it.
Headline results
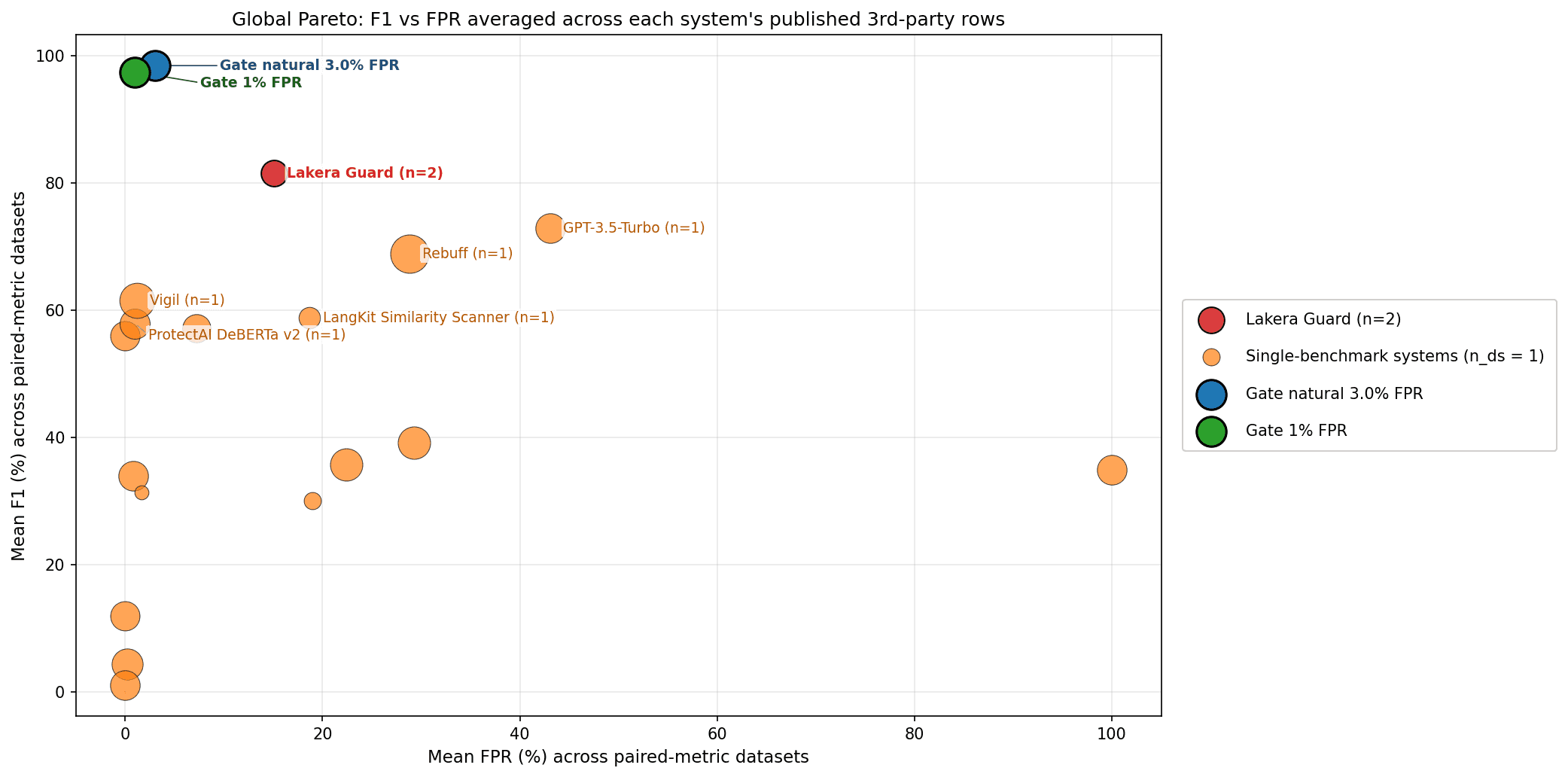
Two numbers carry most of the story.
If we cap false alarms on legitimate user traffic at 1 in 100, Gate AI catches roughly 95 out of every 100 prompt injection attempts across the 16 benchmarks. Relax the cap to 4 in 100 and the catch rate climbs to nearly 99 out of 100.
Against published competitor scores, Gate AI ranks first on 8 of the 16 benchmarks, second on 3, and third on 1. The remaining benchmarks either have no published comparator on a comparable metric, or they sit within statistical noise of the leader.
For technical readers, the headline F1 is 97.4% at the deployable operating point (FPR ≤ 1%) and 98.7% at the unconstrained max-F1 threshold (FPR 4.2%). The full per-dataset breakdown, including precision, recall, and confidence intervals at both micro and macro aggregations, is in the report.
The benign-traffic story
The biggest gap between detectors usually isn't on attack data. Most modern systems catch most attacks. The gap is on benign data: how often a detector mistakenly blocks legitimate user prompts.
Two benchmarks isolate that question. notinject is a corpus of legitimate user requests that look superficially similar to injection attempts, such as questions about sensitive topics, requests for sensitive information phrased neutrally, or prompts that include words common in attack patterns. wildguard-benign is a broader corpus of legitimate prompts from the WildGuard collection.
On both, FPR is the meaningful metric. At Gate's global headline threshold:
| Benchmark | Gate FPR | Lakera Guard FPR (published) |
|---|---|---|
| notinject | 2.06% | 12.4% |
| wildguard-benign | 1.03% | 17.4% |
Lakera Guard is the most-cited commercial competitor in this space; the published Lakera numbers above are from independent academic papers, not vendor blogs. On the benign-only datasets where over-blocking is the failure mode, Gate AI's published FPR is roughly 6× lower on notinject and 17× lower on wildguard-benign.
A note on Lakera's marketing. Lakera's product literature advertises an FPR as low as 0.1–0.2%. That figure comes from Lakera's internal Challenging Moderation Benchmark, with adaptive calibration tuned per customer as part of onboarding. It is neither an out-of-the-box number nor a third-party measurement on a public benchmark. Our matched-FPR comparisons evaluate Lakera at its third-party published FPR on each public benchmark instead.
Head-to-head: Lakera Guard at matched FPR
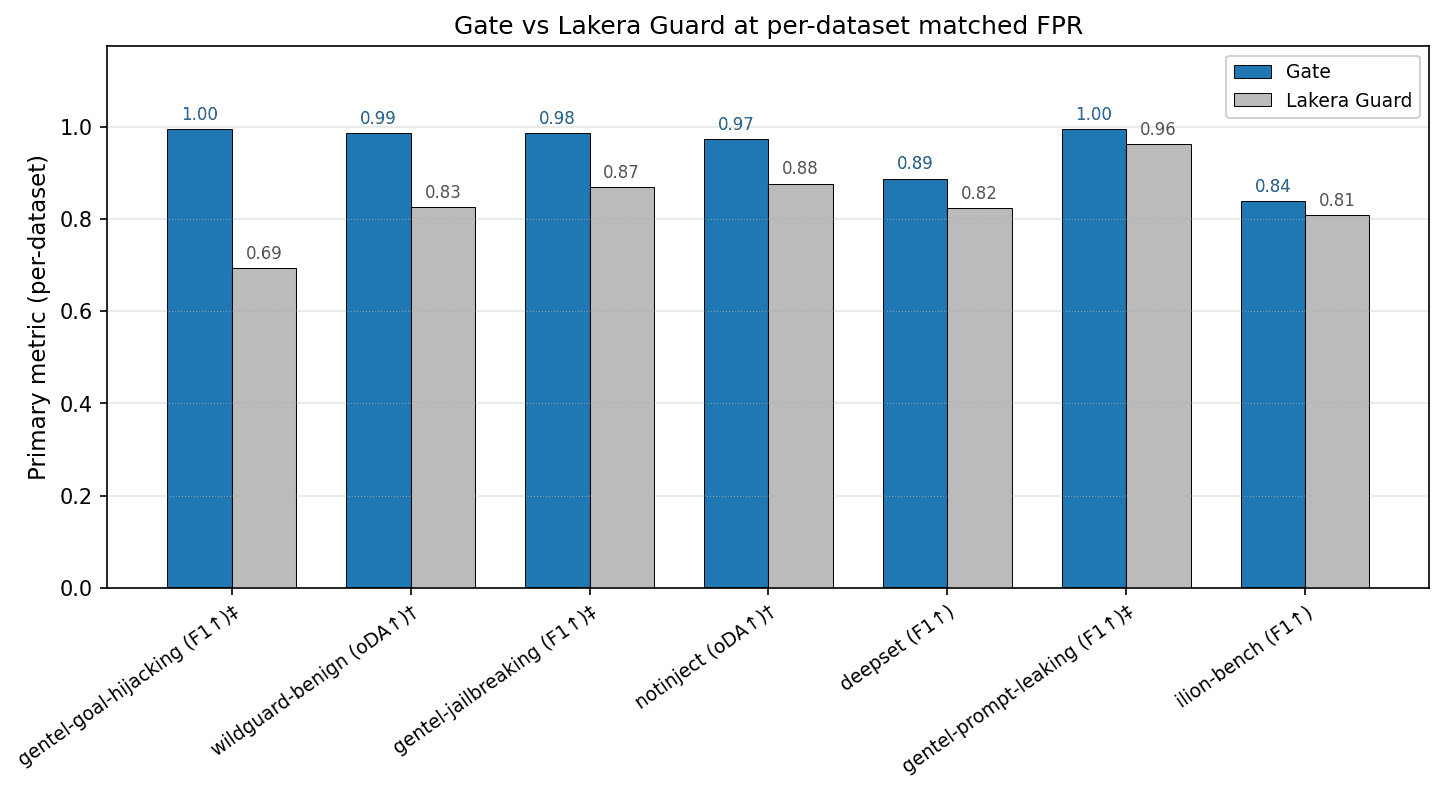
Lakera publishes per-dataset numbers on the broadest set of public benchmarks, so the report carves out a dedicated head-to-head section. The comparison is done at per-dataset matched FPR. Gate's threshold is re-tuned on each benchmark to hit Lakera's published FPR for that benchmark, so the two systems are scored at like-for-like operating points.
At matched FPR, Gate is at or above Lakera Guard on every directly comparable row. On the benchmarks where matching FPR collapses the comparison (notinject and wildguard-benign, where FPR itself is the primary metric), Gate's value at the global headline threshold is reported instead.
The full per-dataset Lakera comparison, including the rows where Lakera's FPR was not published and we matched to a 1% FPR surrogate, is in the report.
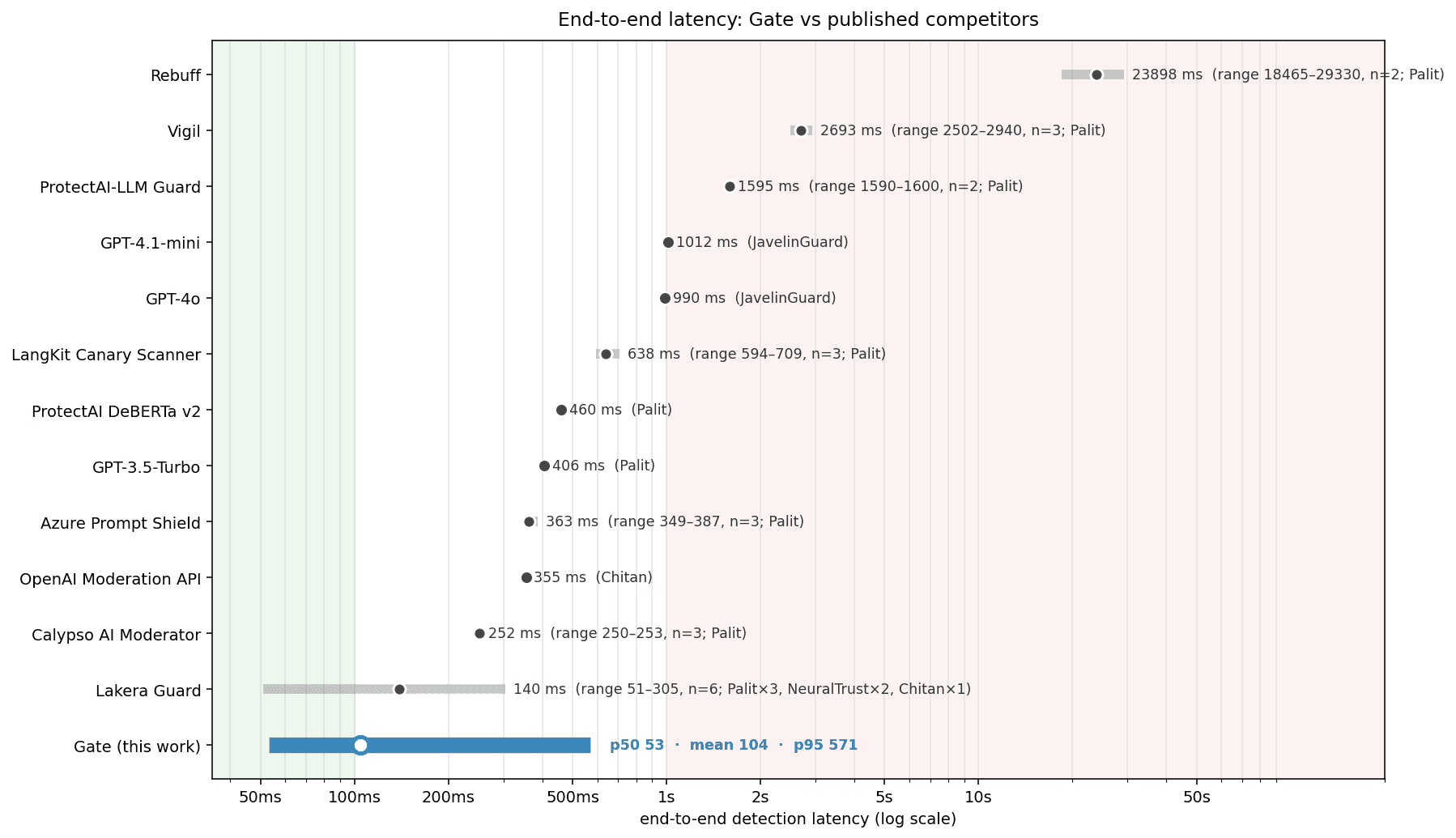
Latency
Detection latency shows up in production, not just on benchmarks. The cascade architecture sends most traffic through a fast first stage and only escalates ambiguous samples to a deeper second-stage analysis. The resulting end-to-end distribution is bimodal:
| Percentile | End-to-end latency |
|---|---|
| p50 (median) | 53ms |
| p90 | 60ms |
| p95 | 571ms |
| p99 | 612ms |
| Mean | 104ms |
The p50 sits at the fast-path latency (the ~90% of requests that resolve at the first stage); the p95 is dominated by the ~10% deferred-mode tail.
Against published competitor latencies, Gate's mean of 104ms is the lowest in the corpus.
What the methodology checks rule out
Three diagnostics back up the headline numbers:
Random-label sanity check. The final decision-stage classifier is retrained from scratch on shuffled labels. AUC near 0.5 on that run is the leak-free signal. Material lift would mean information was leaking from train to test. On Gate's corpus, the shuffled-label AUC was 0.515, near chance.
Leave-one-dataset-out generalization. For each benchmark, the decision-stage classifier is retrained on every other benchmark and evaluated on the held-out one. This stresses cross-source generalization in a way within-trace cross-validation can't. The micro-pooled LODO F1 is 94.6%, a few points below the in-trace 97.4%, consistent with what's expected when training composition shifts.
Sample-size-matched bootstrap intervals. For every competitor whose published evaluation set is smaller than ours on the same benchmark, we draw bootstrap subsamples of matched size from our out-of-fold predictions and report a 95% confidence interval. When the competitor's point estimate sits inside the interval, the comparison is within sampling noise; when it sits outside, the comparison is statistically meaningful at that sample size. Every competitor row in the report carries this bracket.
The report documents several additional diagnostics, including adversarial validation, length-bias correlation, classifier-head agreement, per-fold threshold stability, calibration with isotonic regression, and a pretraining-contamination discussion. Each carries a stated pass criterion or failure mode.
Known weaknesses
The largest unmodelled risk is pretraining contamination of the benchmark corpora themselves. Many of the public datasets we evaluate against were assembled before current foundation models were trained, which means some samples may have leaked into model pretraining data. We discuss this in the report and treat held-out evaluation on attack patterns generated after foundation-model training cutoffs as the most important follow-up work.
We also call out specific datasets where the cascade underperforms. ilion-bench is the worst, with macro F1 in the mid-70s at the global threshold, reflecting an attack distribution the cascade currently overfires on. The report includes the per-source error analysis and the datasets that dominate the hardest top-100 error rows.
Read the report
The full technical report is published as a typeset PDF: Gate AI: LLM Security Benchmark Evaluation Methodology & Results, authored by Ryle Goehausen and Marcus Sousa from the Constellation Network engineering team. It includes:
- Per-dataset leaderboard with citations to every competitor source
- Sample-size-matched bootstrap confidence intervals for every competitor whose published n is smaller than ours
- Latency distribution by input size and against every published competitor
- Full evaluation methodology: cross-validation, threshold selection, aggregation choices, calibration, generalization diagnostics
- Glossary of every metric used
Constellation Gate AI is a security and audit gateway for AI applications. It plugs into any existing AI workflow without code changes and provides prompt-injection defense, a tamper-evident audit trail of every model call, and unified cost and usage visibility across major commercial model APIs and open-weight models. Early access registration is open at constellationgate.ai.


